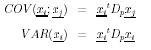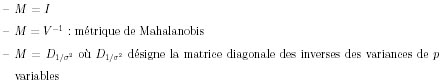|
Analyse en Composantes Principales
|
|
|
1 - Notations
1
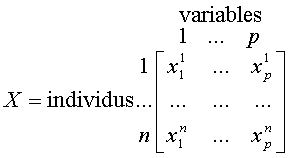
- Notations Les données que l'on doit traiter par l'ACP sont stockées dans un tableau X de type individus/variables de la forme suivante :
On a alors :
Le problème est
que si on analyse directement la matrice X, les résultats seraient
faussés par les valeurs relatives des variables (Par exemple
si les valeurs ont été mesurées dans des unités
différentes). Préparer les données pour le traitement
consiste donc à transformer le tableau de données pour
réduire ces effets.
Dp est diagonale et chacun
des éléments de la diagonale est égal à
1/N .
les métriques les
plus couramment utilisées sont : 3 - Projections sur un sous-espace L'ACP consiste à
projeter les points sur une droite, un plan...un sous-espace à
s dimensions (avec s < p) choisi de façon à optimiser
un certain critère. Intuitivement, on cherchera le sous-espace
donnant la meilleure visualisation possible de notre nuage de points.
Un bon choix consiste à rechercher la plus grande dispersion
(le plus grand étalement) possible des projections dans le
sousespace choisi. On est amené ainsi à chercher une
rotation de notre système d'axes initial (les variables) permettant
de mieux voir notre nuage. Définissons u1 le vecteur unitaire
(i.e. de norme 1; u1'u1=1) recherché; c'est le vecteur présentant
la plus grande dispersion des projections.
Il est donc clair ici
que trouver les valeurs de fi les plus proches de celles de ei dans
un nouvel espace, revient àmaximiser la dispersion (ou inertie
totale) des fi.
puisque g = 0 (les variables sont centrèes). En utilisant l'écriture matricielle, on montre facilement que :
où P est la matrice permettant de projeter le nuage de l'espace initial vers celui de l'espace des individus projetés.
4
- Axes principaux
Le but est
donc de trouver a maximisant Tr(VMP). A l’axe principal a est associé le facteur principal u = Ma. En partant du fait que a est déterminé par le vecteur propre de MV correspondant, on montre que u est déterminé par les vecteurs propres de VM. 6
- Composantes principales ci = Xui
|
|